Keine freien Inodes mehr
Symptomatik
Wenn auf einem Server laufende Dienste nicht mehr erreichbar sind, begibt man sich auf Ursachenforschung. Ausgangspunkt ist dann meist ein Login über ssh und die Abfrage des Status des betreffenden Dienstes per systemctl.. Dabei tritt dann zu Tage, dass der betreffende Dienst nicht läuft. Mit viel Glück kann man aus der Statusmeldung auch die Ursache ablesen. Spätestens der Versuch, den Dienst über sudo neu zu starten, öffnet einem die Augen. Dieser schlägt mit der Meldung fehl, dass auf dem Gerät kein Speicherplatz zur Verfügung steht.
Auch wenn die Fehlermeldung eindeutig ist, wird man meist die Angabe überprüfen wollen. Üblicherweise schaut man sich dafür die Ausgabe von df -h an.
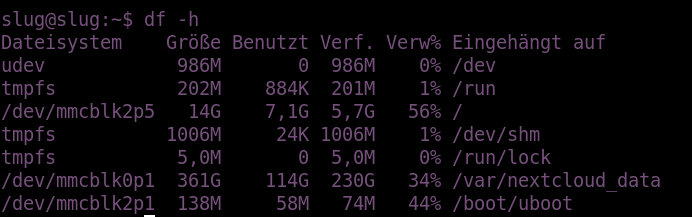
Laut der Ausgabe ist noch ausreichend Speicherplatz vorhanden. Ist also die Fehlermeldung falsch? Schauen wir uns dazu die Ausgabe von df -i an, die uns die Verteilung der zur Verfügung stehenden Inodes anzeigt.
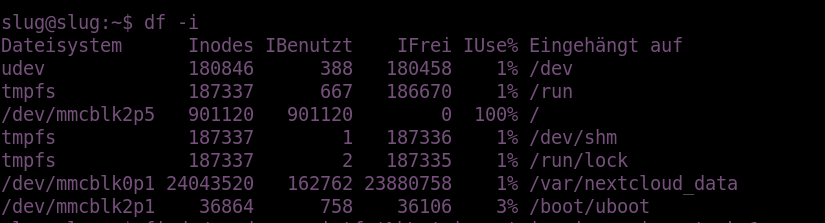
Wie wir sehen, stehen auf dem Dateisystem keine Inodes mehr zur Verfügung.
Ursachenforschung
Um das System wieder in Gang zu bringen, werden wir wohl oder übel Dateien löschen müssen. In aller Regel sind dafür Root-Rechte erforderlich. Der Weg über sudo scheidet aus, da dabei eine temporäre Datei angelegt wird, was aber wegen der fehlenden Inodes nicht möglich ist. Je nach Konfiguration des Systems ist eventuell noch der Weg über su möglich. Geht auch das nicht, bleibt nur die Nutzung eines Live-Systems oder der Ausbau des betroffenen Datenträgers.
In jedem Fall begeben wir uns als Root auf die Suche nach dem Verzeichnis, welches die meisten Inodes verbraucht. Wir fangen mit der Suche im Wurzelverzeichnis an.
for i in /*; do echo -ne "$i\r\t\t\t\t"; find $i 2>/dev/zero | wc -l; done
Die Befehlsfolge zeigt uns, dass mehr als 700000 Inodes im Verzeichnis /var verbraucht werden.
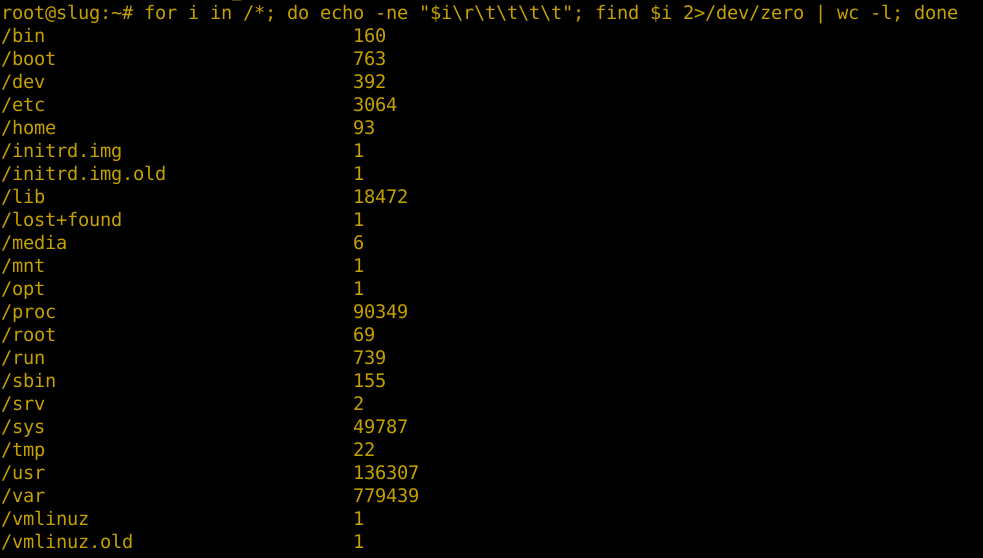
Von hier aus hangeln wir uns Verzeichnis für Verzeichnis weiter nach unten, bis wir das Verzeichnis gefunden haben, welches diese Menge an Inodes verbraucht.
for i in /var/*; do echo -ne "$i\r\t\t\t\t"; find $i 2>/dev/zero | wc -l; done
Im meinem Fall war die höchste Anzahl verbrauchter Inodes im Verzeichnis /var/log/sudo-io/00 zu finden.

Ein kurzer Blick in die in dem Verzeichnis enthaltenen Dateien offenbarte dann auch den eigentlichen Verursacher. Der Dienst motion legte in diesem Fall neu erkannte Bewegungsvideos auf dem Webserver ab und sudo loggte dies brav mit. Also erst mal durch Löschen der Dateien Platz schaffen und das System neu booten.
Beseitigung der Ursache
Damit ist aber die eigentliche Ursache noch nicht beseitigt. Über kurz oder lang wird das System wieder an die Grenze der Inodes kommen, wenn das Mitloggen der sudo-Aktivitäten von motion nicht gebändigt wird. Im vorliegenden Fall hab ich in der Datei /etc/sudoers einfach die Optionen NOLOG_INPUT: und NOLOG_OUTPUT: hinzugefügt.